LookFar Labs28 July 2016
How and When to Implement Binary Search Trees
No, they’re not just something you’ll get asked about in tech interviews
If the patterns you write in your code are not efficient, you are stealing time from your users and in essence, draining them of their precious life force. If “developer” secretly meant “code vampire” this would be fine; but as it stands, wasteful code accomplishes nothing beyond annoying your users. Use efficient code, and don’t steal life force!
How many times have you written this structure?
var searchKey = “john”
for(elem in array) {
if(elem.name == searchKey) {
// DO SOMETHING
break;
}
}
This code gets the job done in a logical way. I have a list of elements and each one has a name property, so to find the one I want, I’ll just run through the whole list until I find the one that matches.
However, this is NOT the most efficient way. Occasionally, the element you are looking for will be at the beginning of the array, but just as often, it will be at the end. This isn’t a big deal for an array of 10 or 20 elements, but what about 1000, 10000, or 1000000? How can we bring down the average time the computer spends looking for the correct element? There are many techniques to accomplish this, but today we are going to look at the applications of the Binary Search Tree.
When to Use Binary Search Trees
Implementing a binary search tree is useful in any situation where the elements can be compared in a less than / greater than manner. For our example, we’ll use alphabetical order as our criteria for whether an element is greater than or less than another element (eg. “alan” < “bob” < “dave” < “john” < “kyle” < “leonard” < “zack”).
A tree is a set of data elements connected in a parent/child pattern. For example:
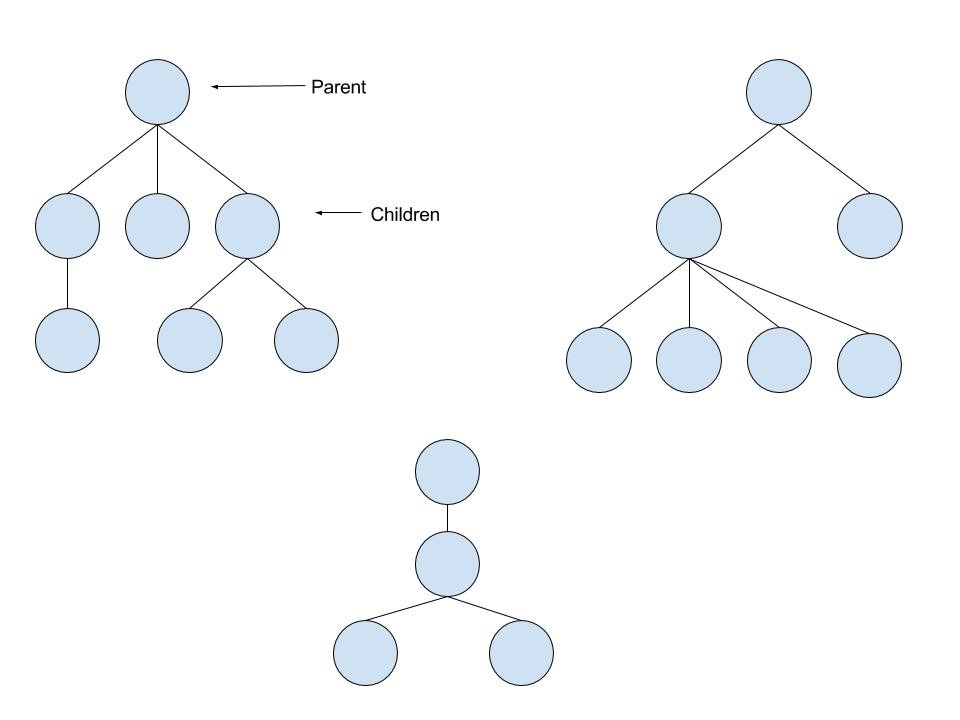
A binary tree is a tree structure in which each data element (node) has at most 2 children.
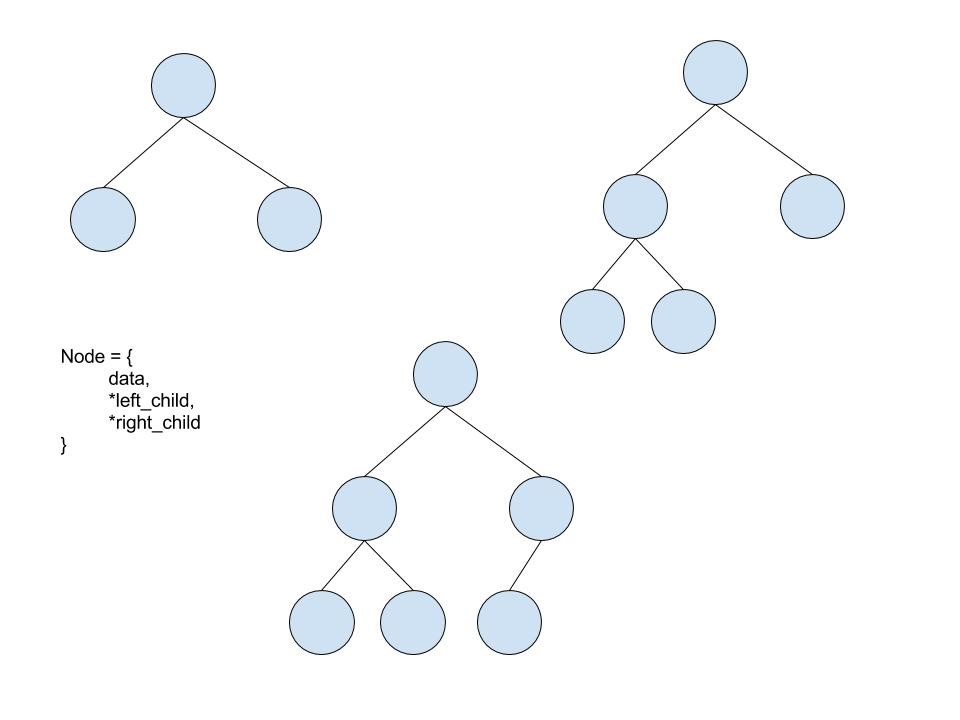
A binary search tree is a binary tree in which any child node or subtree to the left is less than the parent node, and any child node or subtree to the right is greater than the parent node. Here’s a handy visualization:
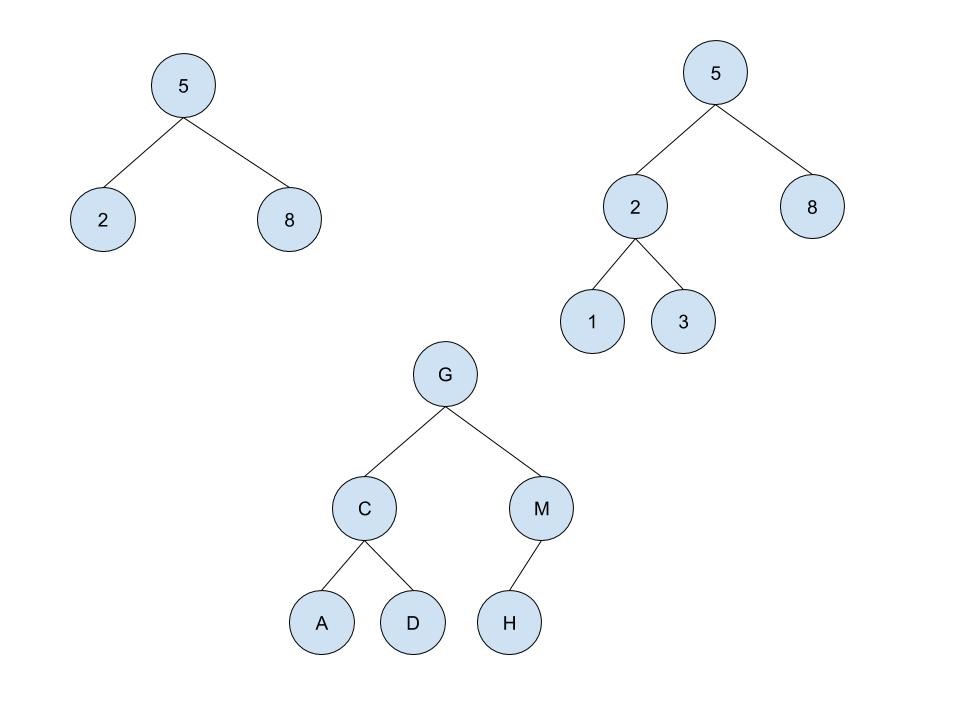
Great! So why does any of this matter? Well, let’s see how we would search.
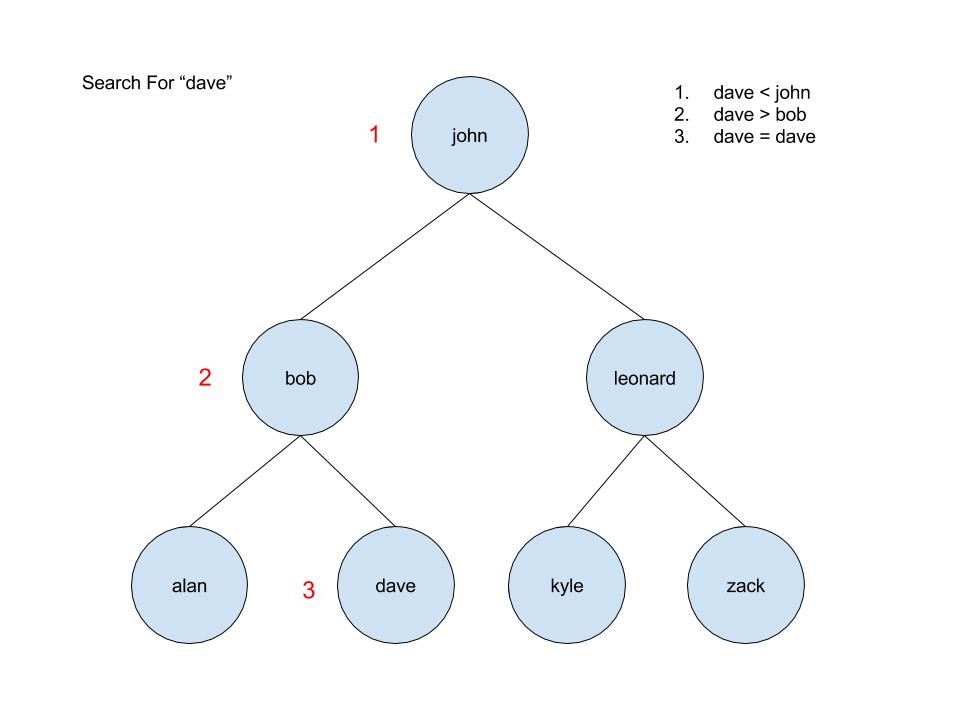
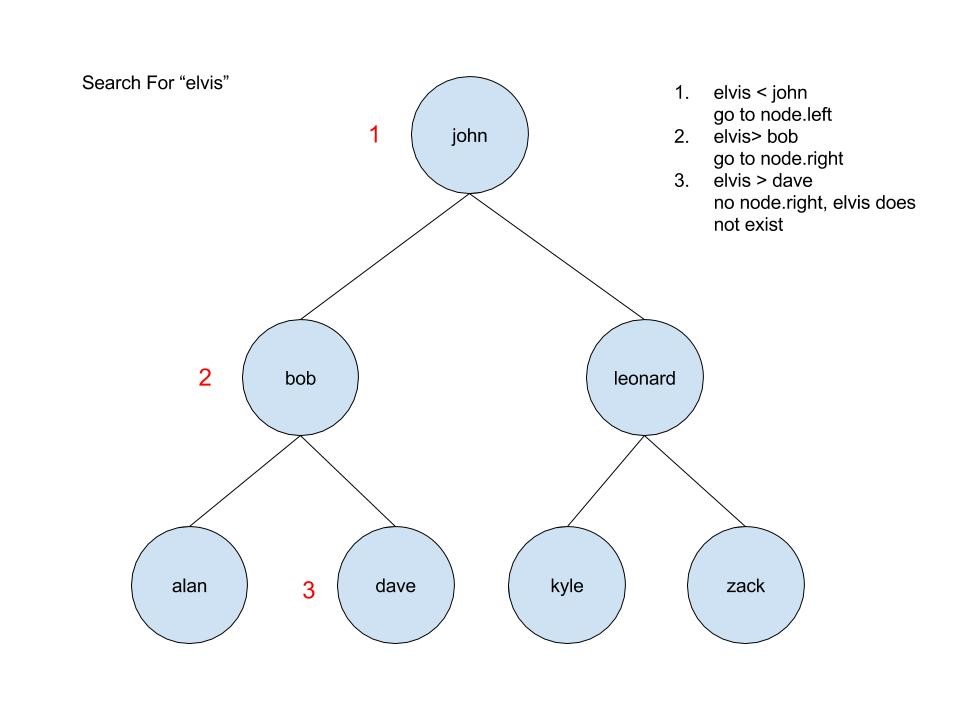
Start at the root. If the search key is less than the index key of the element, go to the left child. If the search key is greater than the index key of the element, go to the right child.
This process continues until the search key matches the index key (and the element is found), or until the end of the tree is found (in which case the element does not exist). In three comparisons, we have either found the element, or we can be certain that it does not exist. For the array, it will take us 7 comparisons to get the same information, and the larger the array, the more time we will save by using a binary search tree.
So searching is definitely faster, but what about other operations? On average, a binary search tree will beat an array in the number of operations it takes to insert or delete an element. If you are inserting an element to the end of an array, all you have to do is put the data in the the first available memory address myArray[myArray.length] (this is more akin to pushing onto a stack). However, if you have to insert at the beginning of an array, you will need to shift every element over. The same is true for deletion. If the element is at the end (like popping off a stack), then you simply change the stored length of the array. But if you delete the first element, all of the others will need to be shifted. Since the binary search tree does not require its elements to be stored in a contiguous block of memory, inserting or deleting a node can be done by simply adjusting some pointers. Remember that each node is a struct containing data and pointers to left_child and right_child.
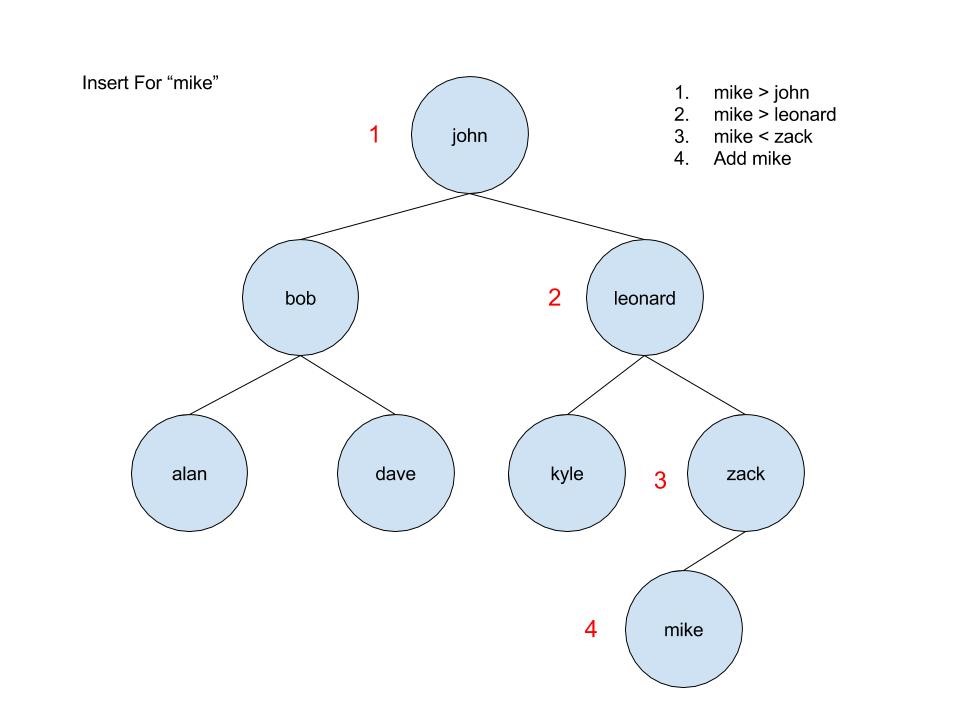
So, why would I ever use an array?
A few reasons. One of the greatest advantages of using arrays is that element access can be done in constant time. For example, if you want to get the fifth element from an array, you take the starting memory address and add (index * element_size). If our memory address starts at 0 and this is an array of 8-bit characters, the fifth element would be at memory address 0+(4*8) = 32. It doesn’t matter how many elements are in the array, this access time remains constant. If we were to use a BST in the same scenario there would be no way to get to the fifth element without starting at the root node and traversing to the fifth element. Also, since the tree is not a single-dimensional construct, you would need to define exactly what you mean by the “fifth” element…and that introduces us to depth-first vs breadth-first traversal (a big, big topic that we may cover at a later date).
Also, if your data is already in array form (maybe it was returned from the database in this way), it is possible that the time it would take to set up the BST the first time may take longer than the worst case search of that array. However, you have to consider whether you will be searching the array again and again. If that is the case, you may want to build your BST the first time and then use it for searches after that. Also, if your array is very, very long, it is probably worth it to use a BST.
Finally, let’s talk about worst case scenarios for BSTs. What happens if the array is in alphabetical order and we build our BST?
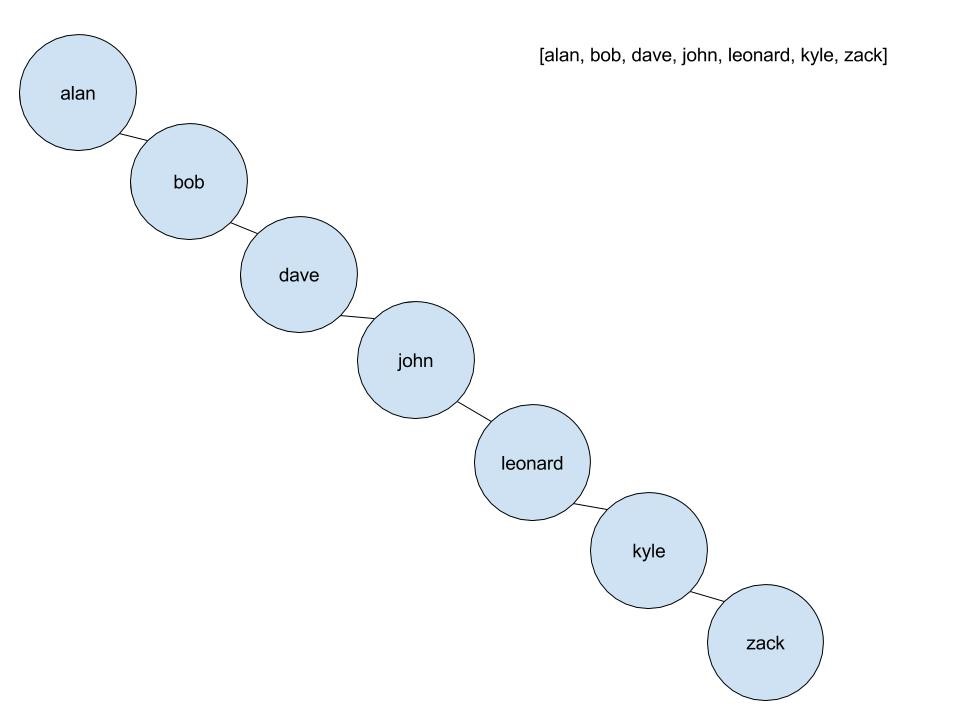
This is still a BST, but it is “unbalanced.” In this state, a BST is reduced to its worst case, which is the same as an array for searches. In order to promote balanced tree construction, the B-Tree and Red-Black Tree were invented. They are both special cases of the general binary search tree seen here, but they use a few balancing procedures to make sure you are gaining the full benefit of using a BST.
And that about covers the basics! We’ll be revisiting some of these concepts in the future, so stay tuned for some more in-depth coverage of comp sci topics.
Written by
 Why Conduct a UX Review
Why Conduct a UX Review  Are your software maintenance costs outweighing the software’s value?
Are your software maintenance costs outweighing the software’s value?